|
|
Many matrices, and in particular node- and modified-node admittance matrices, tend to be nearly symmetric and nearly diagonally dominant. For these matrices, it is a good idea to select pivots from the diagonal. With this option enabled, this is exactly what happens, though if no satisfactory pivot can be found on the diagonal, an off-diagonal pivot will be used. If this option is disabled, Sparse does not preferentially search the diagonal. Because of this, Sparse has a wider variety of pivot candidates available, and so presumably fewer fill-ins will be created. However, the initial pivot selection process will take considerably longer. If working with node admittance matrices, or other matrices with a strong diagonal, it is probably best to use DIAGONAL_PIVOTING for two reasons. First, accuracy will be better because pivots will be chosen from the large diagonal elements, thus reducing the chance of growth. Second, a near optimal ordering will be chosen quickly. If the class of matrices you are working with does not have a strong diagonal, do not use DIAGONAL_PIVOTING, but consider using a larger threshold. When DIAGONAL_PIVOTING is turned off, the following options and constants are not used: MODIFIED_MARKOWITZ, MAX_MARKOWITZ_TIES, and TIES_MULTIPLIER. |
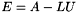 . If this bound is very high after applying spOrderAndFactor(), then the pivot threshold should be raised. If the bound increases greatly after using spFactor(), then the matrix should probably be reordered. Recomend NO.
. If this bound is very high after applying spOrderAndFactor(), then the pivot threshold should be raised. If the bound increases greatly after using spFactor(), then the matrix should probably be reordered. Recomend NO. 